Paper Overview
Eight sections covering the full spectrum from foundation simulation to embodied action.
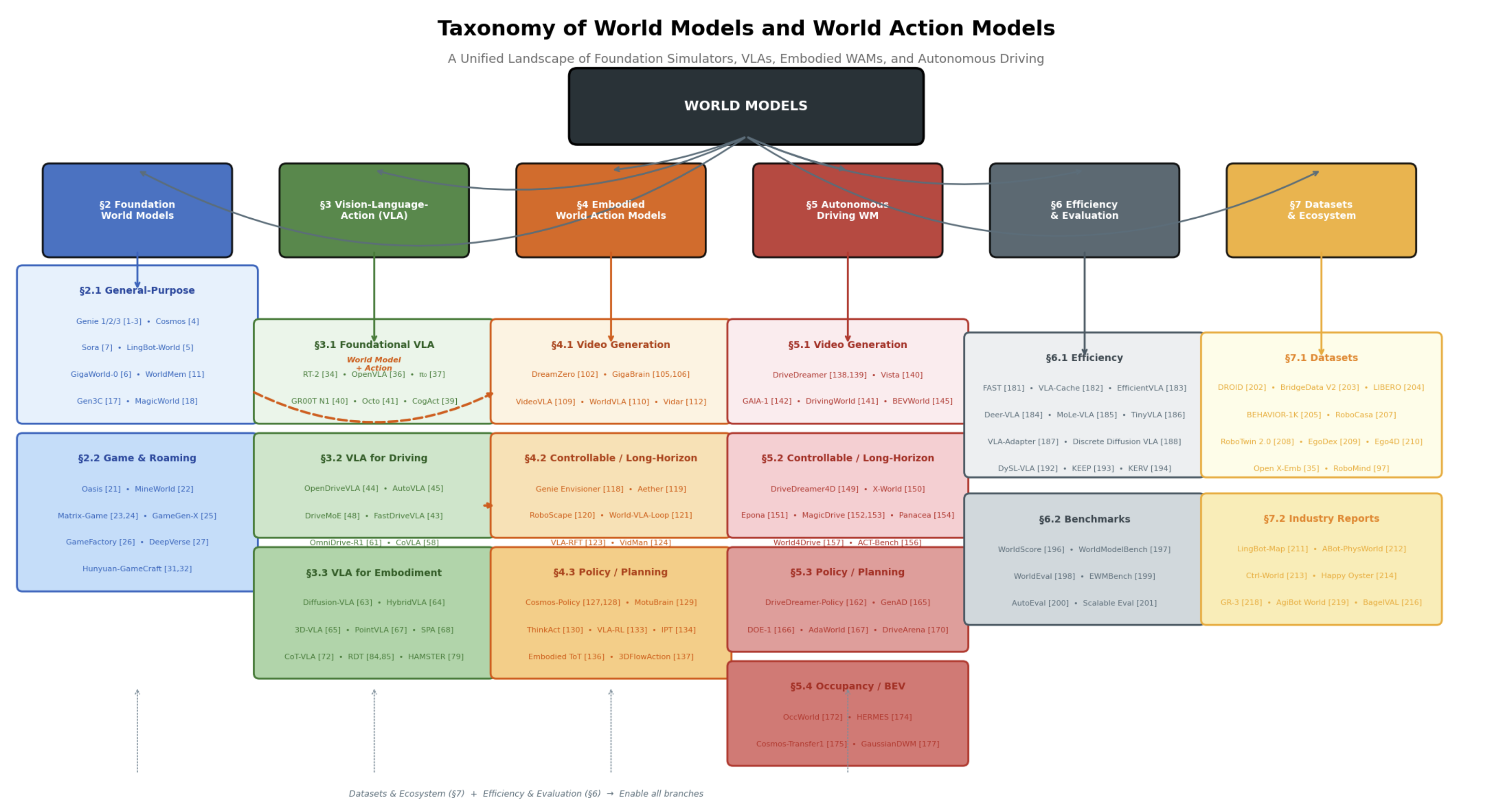
Introduction
Evolution from recurrent world models to large-scale generative simulators and the convergence of world models with VLA into WAMs.
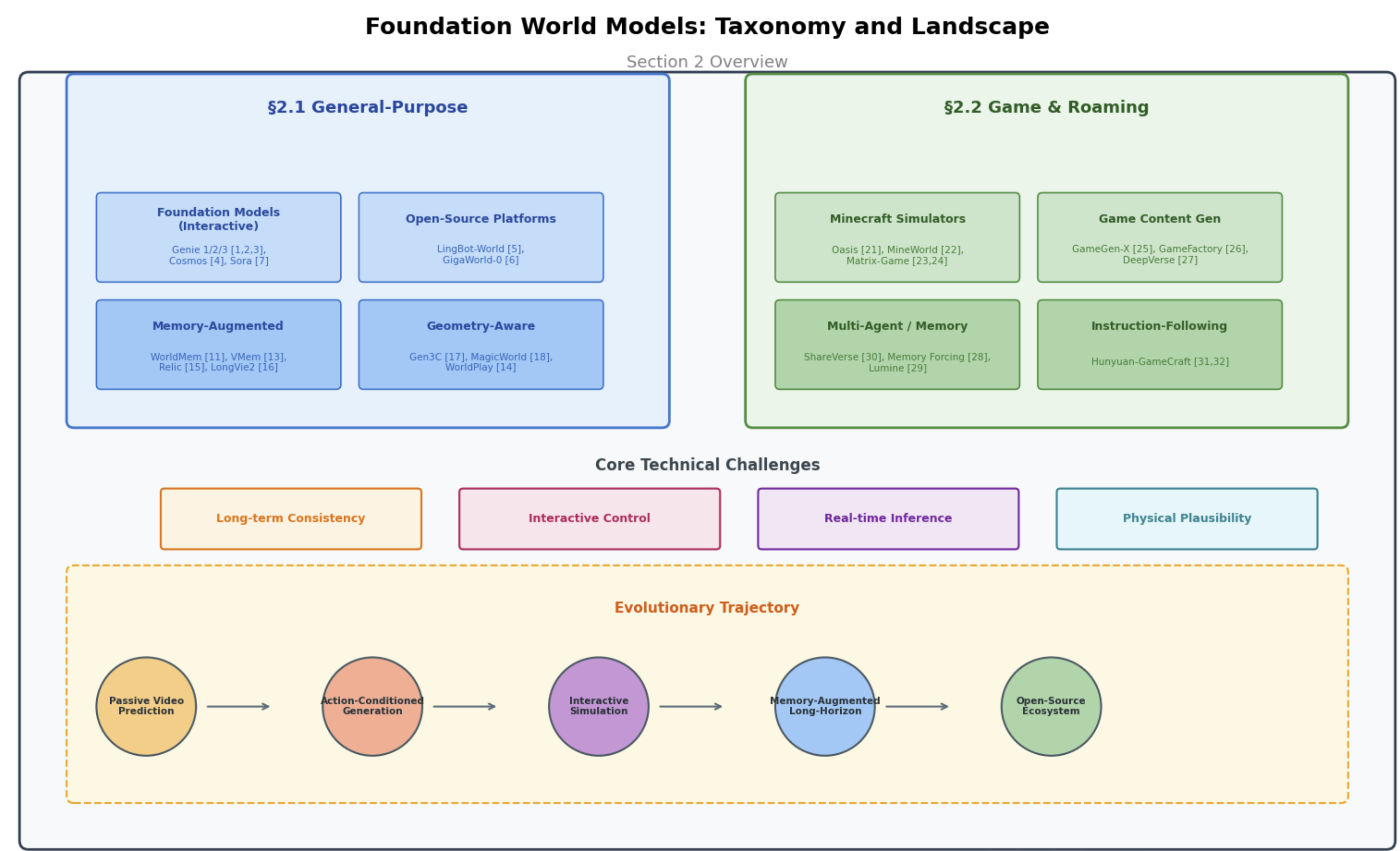
Foundation World Models
General-purpose interactive simulators (Genie, Cosmos, Sora) and game-specific environments (Oasis, Matrix-Game, GameGen-X).
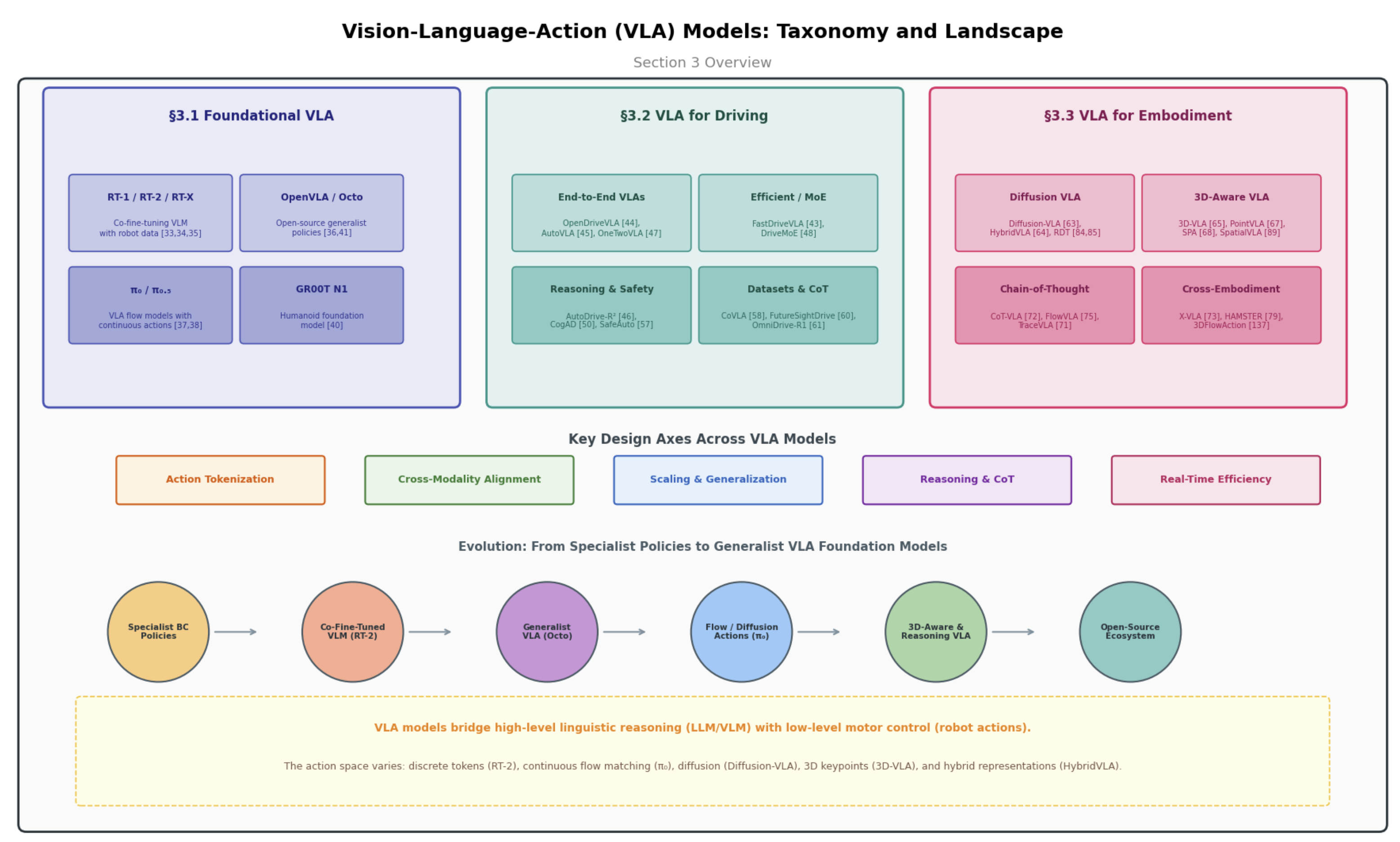
Vision-Language-Action Models
Foundational architectures (RT-2, π₀, OpenVLA), driving-specific VLAs, and embodied manipulation policies (Diffusion-VLA, 3D-VLA, RDT).
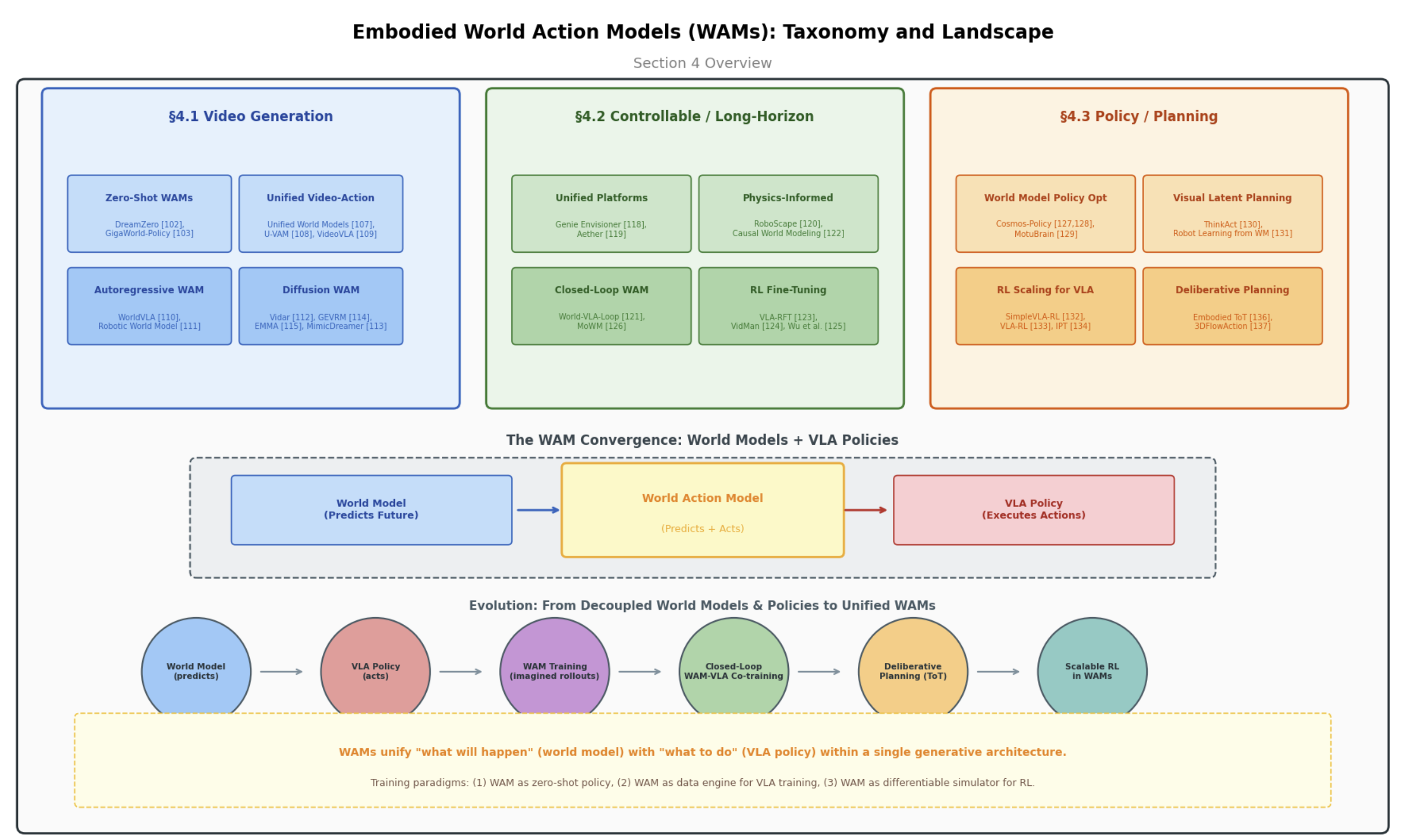
Embodied World Action Models
Unified video-action pretraining (DreamZero, Unified World Models), controllable simulation (RoboScape), and policy optimization (Cosmos-Policy, ThinkAct).
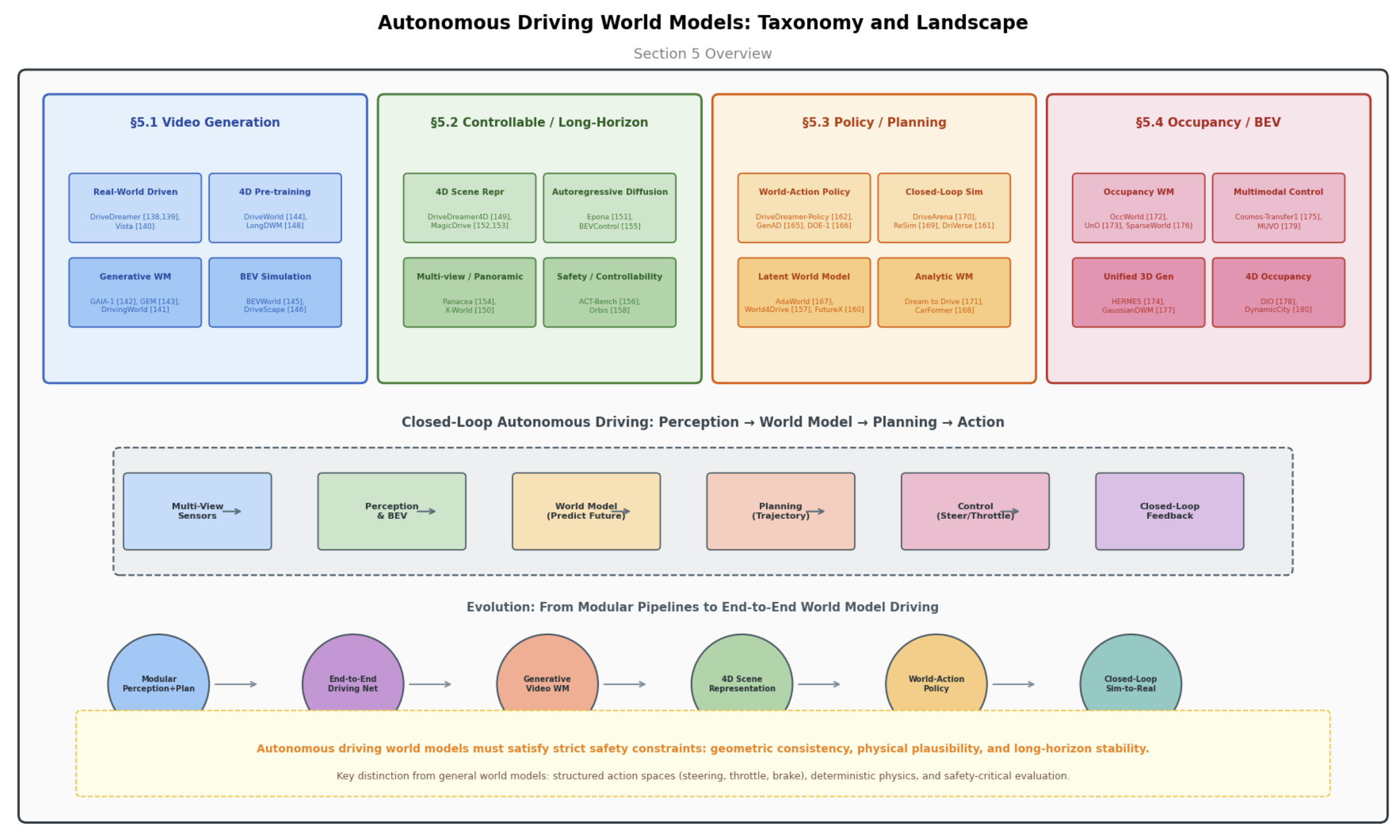
Autonomous Driving World Models
Driving video generation (DriveDreamer, GAIA-1), closed-loop simulation (DriveArena, Epona), planning (GenAD, DOE-1), and occupancy/BEV (OccWorld, HERMES).
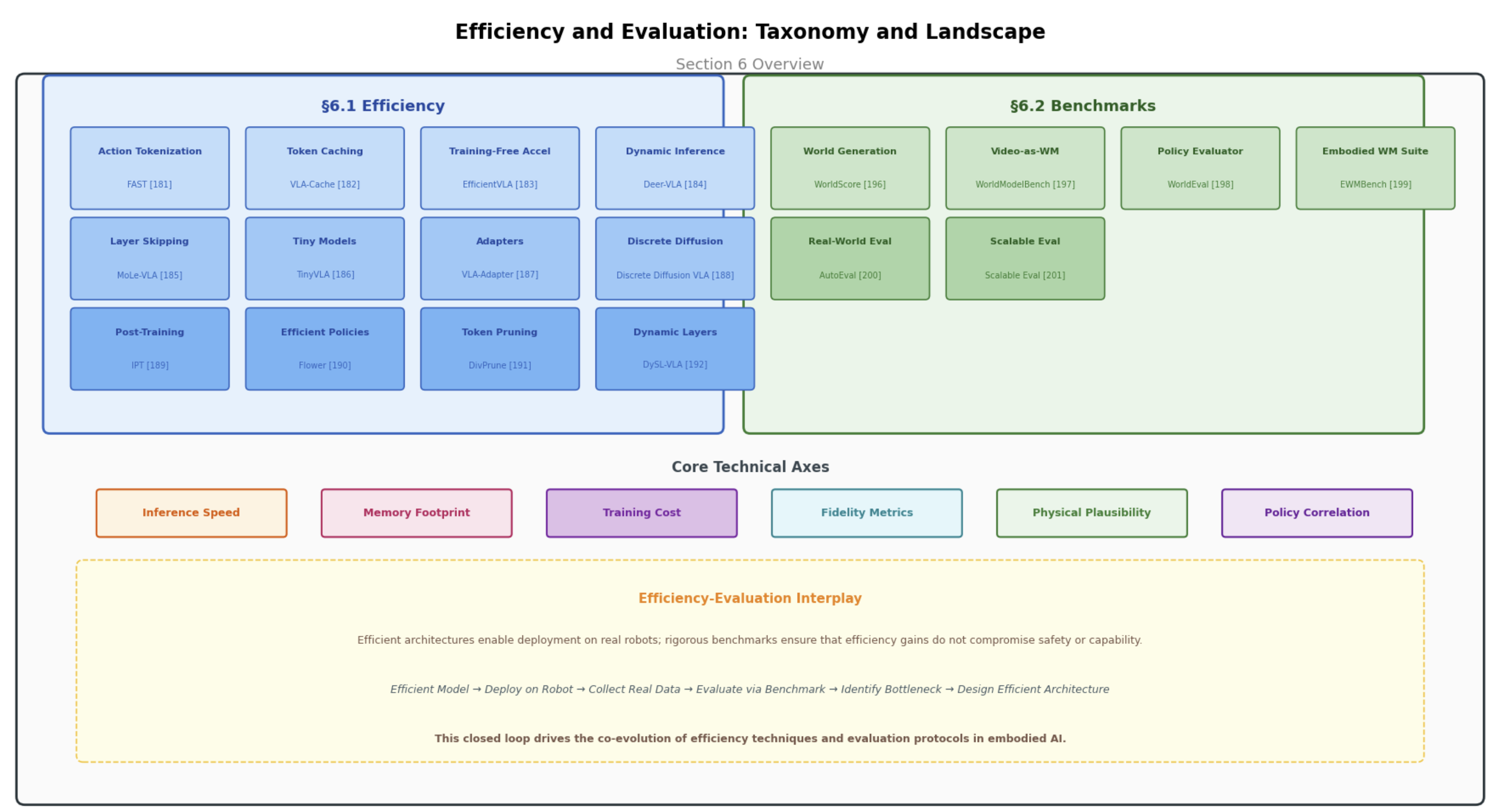
Efficiency and Evaluation
Computational acceleration (FAST, VLA-Cache, MoLe-VLA, TinyVLA) and benchmarks (WorldScore, WorldEval, AutoEval).
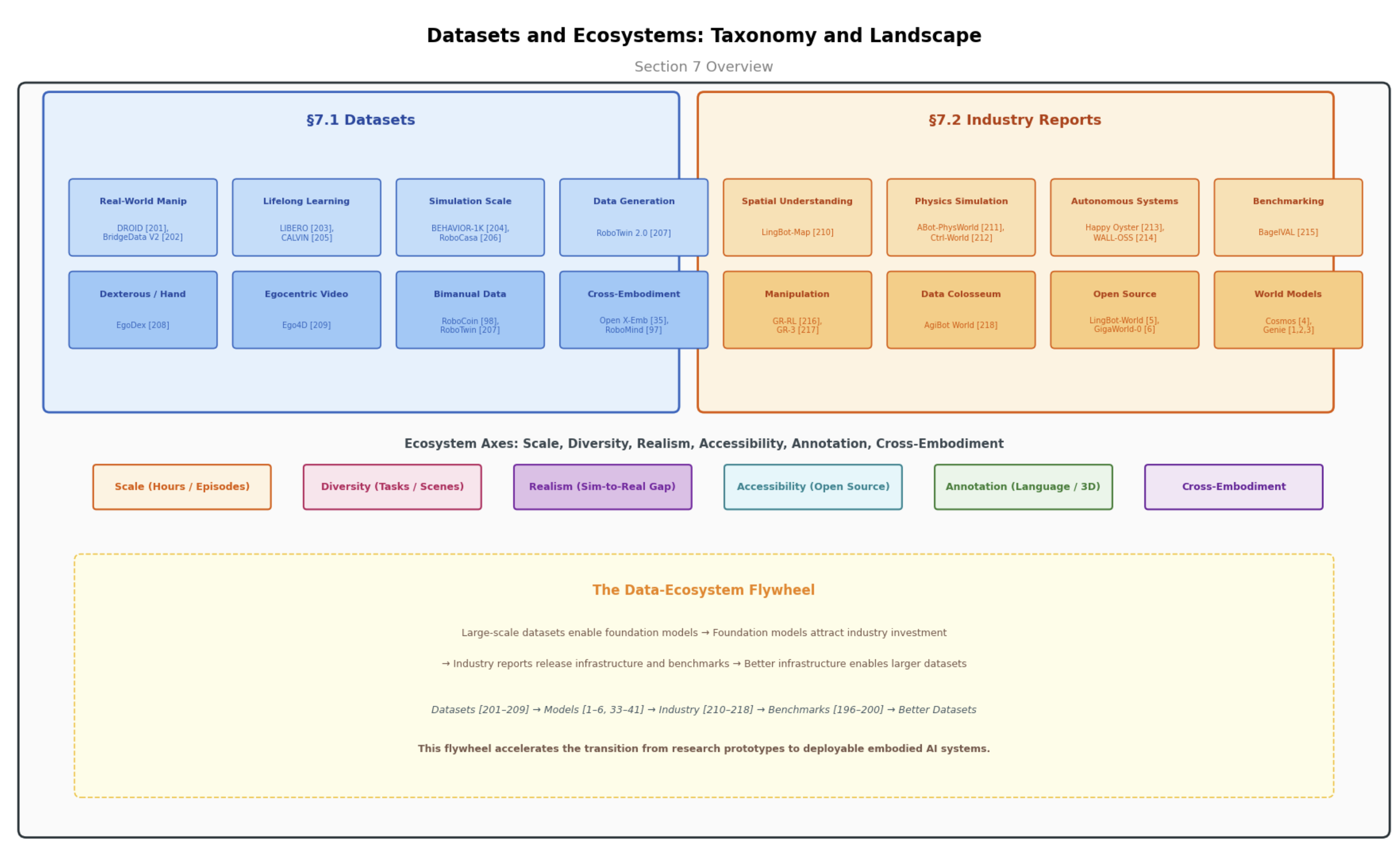
Datasets and Ecosystems
Large-scale robot learning corpora (DROID, BridgeData, LIBERO, BEHAVIOR-1K) and industry technical reports (LingBot, GR-3, AgiBot).
Conclusion & Future Directions
Open challenges in physical consistency, cross-embodiment generalization, safety verification, sim-to-real evaluation, and standardized open ecosystems.